Marek70 pisze:Mam jeszcze jedno pytanie do Ciebie: Chodzi mi o trafność powiązań DNA (nadłuższy bloki w cM, ilość SNP) z Twojego praktycznego doświadczenia w tej dziedzinie?
Po pierwsze należy pamiętać, że to zależy w dość dużym stopniu od tzw. wsobności populacji. W populacjach, gdzie wszyscy są relatywnie blisko spokrewnieni ze sobą (czyli np. Aszkenazyjczycy, Islandczycy, czy nawet Finowie) będzie to wyglądało inaczej niż np. w przypadku Włochów czy Francuzów. Czyli wynik, który np. dla przeciętnego Francuza jest w miarę wysoki i oznacza stosunkowo bliskie pokrewieństwo (np. wspólny przodek żyjący zaledwie cztery pokolenia temu) dla przeciętnego Aszkenazyjczyka lub Fina może już nie być wcale taki ciekawy, bo tam wszyscy wywodzą się ze stosunkowo małej i niezbyt odległej czasowo "grupy założycielskiej", więc podobieństwo genetyczne nawet między bardzo odległymi krewnymi jest stosunkowo wysokie.
W Polsce ten poziom "wsobności" nie jest zbyt duży, ale oczywiście zdarzają się pewnie jakieś specyficzne regiony wiejskie, gdzie wyglądać to może trochę inaczej, więc czasami trzeba brać na to dodatkową poprawkę. W mojej szeroko pojętej rodzinie mam w tej chwili przebadane autosomalnie 24 osoby, które spokrewnione są ze sobą w bardzo różny sposób, więc na tej podstawie mogę mniej więcej określić, jakie wyniki świadczą o niemal pewnym pokrewieństwie w tzw. "genealogicznych ramach czasowych", a jakie dają tylko stosunkowo niewielką szansę na to, że mamy do czynienia z takim właśnie potencjalnym krewnym, który jest (przynajmniej teoretycznie) "identyfikowalny" genealogicznie. Jeśli więc pojawia się "match", który ma ponad 80 cM wspólnego DNA (przy najdłuższym bloku powyżej 30 cM), to jest to niemal pewny krewniak, z którym mamy wspólnego przodka żyjącego w ciągu ostatnich 200 lat (choć nawet wtedy trafiają się "fałszywi krewniacy", patrz poniżej). Przy 60-80 cM (i najdłuższym bloku powyżej 20 cM), szanse na pokrewieństwo w "genealogicznych ramach czasowych" są stosunkowo duże, ale istnieje już spore ryzyko, że jest to wynik "fałszywie pozytywny" (w tym sensie, że pokrewieństwo może być zbyt odległe, aby można je było kiedykolwiek zweryfikować przy użyciu tradycyjnych narzędzi genealogicznych). Wśród wyników poniżej 60 cM (i najdłuższym bloku poniżej 20 cM) będą już zdecydowanie przeważać ci "nieweryfikowalni genealogicznie" bardzo odlegli "krewniacy" (ale mogą też się wśród nich oczywiście znajdować "prawdziwi krewniacy").
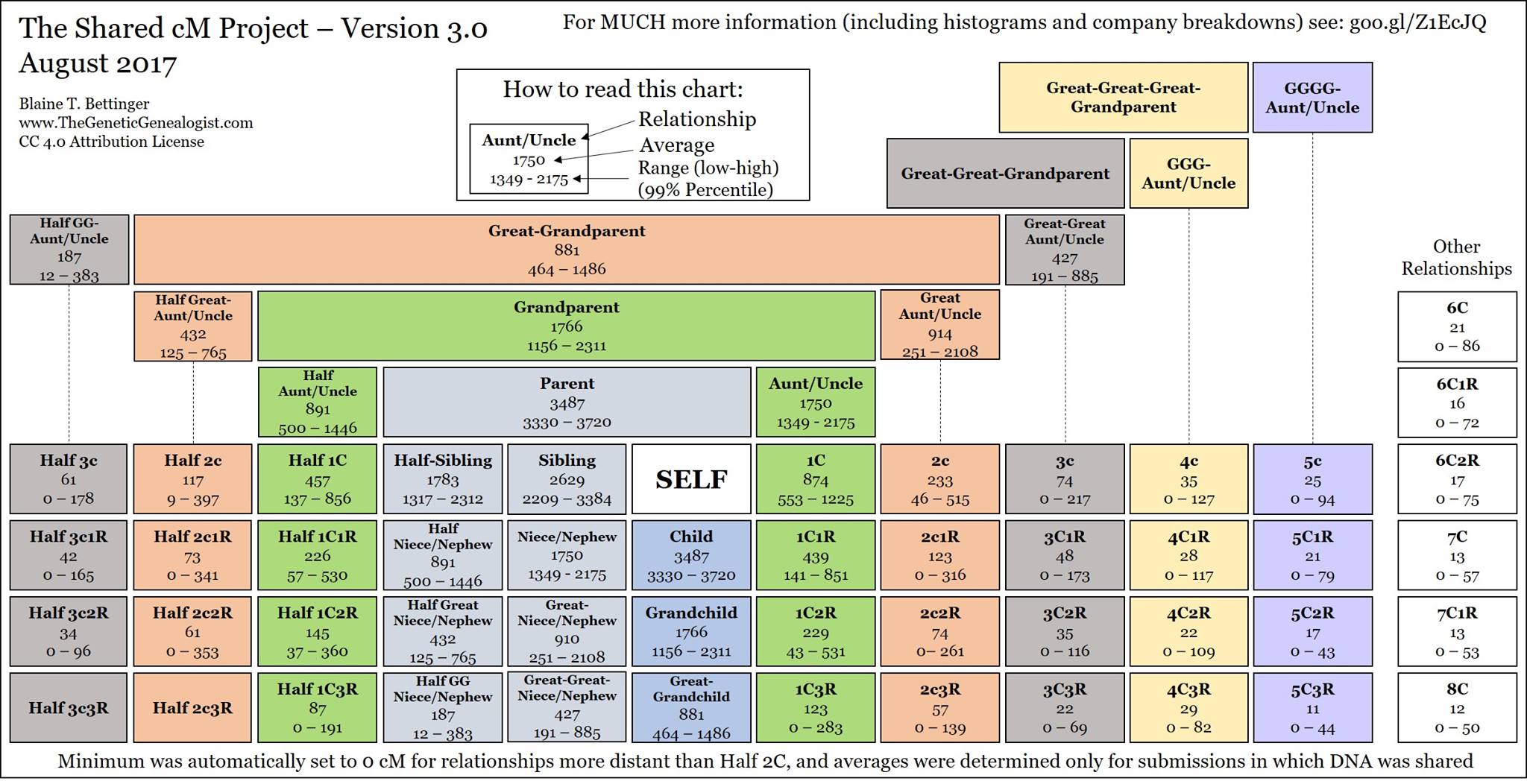
Przy okazji powinienem też wspomnieć, że tak w zasadzie, to moje doświadczenia w tym względzie są jak najbardziej zgodne z tabelą wyników dostępną w sieci:
https://isogg.org/w/images/b/bf/Shared_cM_version_3.jpg
W tej tabeli warto zwrócić przede wszystkim uwagę na fakt, że już w przypadku teoretycznego trzeciego kuzyna (czyli praprawnuka mojego prapradziadka), a nawet w przypadku drugiego kuzyna z jednym przesunięciem (czyli np. praprawnuka mojego pradziadka) istnieje niewielkie ryzyko, że nie pojawi się on w ogóle na liście moich autosomalnych "matchów" (jeśli oczywiście podda się takiemu testowi), bo będziemy mieli ze sobą zbyt mało wspólnego DNA. Z drugiej strony istnieje jeszcze większe prawdopodobieństwo, że na tej mojej liście "matchów" znajdą się osoby, które są ze mną bardzo odlegle spokrewnione, np. mają ze mną najbliższego wspólnego przodka ponad 10 pokoleń temu temu (a więc tak właściwie są na ogół "nieprzydatni" z czysto genealogicznego punktu widzenia).
Istnieją sposoby na to, żeby nieco ułatwić sobie odróżnianie "prawdziwych" matchów od tych "mniej prawdziwych" (czyli spokrewnionych z nami znacznie odleglej niż na to wskazują ich wyniki DNA). Chodzi np. o poruszany niedawno w tym wątku temat "fazowania" wyników DNA, co osiąga się najczęściej dzięki porównaniu wyników dzieci i rodziców, i co przede wszystkim znacznie zmniejsza ryzyko otrzymywania tzw. fałszywych bloków wspólnego DNA (powstających na skutek nakładania się na siebie wyników z dwóch różnych chromosomów tej samej pary). Innym sposobem ułatwiającym identyfikację "prawdziwych" krewniaków jest testowanie znanych krewnych z różnych linii. Jeśli wtedy np. mam jakiegoś "matcha" wspólnego z moimi kuzynami z określonej linii, to wówczas znacznie rośnie prawdopodobieństwo, że ów "match" jest rzeczywiście moim krewniakiem, i w dodatku jestem od raz w stanie wskazać konkretną linię moich przodków, z którą ten "match" powinien być spokrewniony (co ułatwia dalsze poszukiwanie łączących nas wspólnych przodków).
Na koniec podam może kilka praktycznych przykładów z mojej rodziny. Moim najdalszym znanym krewnym, którego udało mi się przetestować, jest mój "piąty kuzyn" (ang. fifth cousin), z których mam wspólnych 4xpradziadków, urodzonych odpowiednio w r. 1782 i 1795. Tak właściwie, to jestem z nim dodatkowo spokrewniony przez kilku dalszych niespokrewnionych ze sobą moich przodków (5x i 6x pradziadków), co może odrobinkę przyczyniać się do zwiększenia całkowitej długości wspólnego DNA (i stanowi też nawiązanie do powyższej uwagi na temat wsobności niektórych populacji wiejskich). Ten kuzyn jest odlegle spokrewniony z 9 przetestowanymi członkami mojej rodziny, i poniżej przedstawiam ich wyniki (w kolejności: całkowita długość wspólnego DNA w cM, najdłuższy wspólny blok w cM, i stopień pokrewieństwa, gdzie np. 4C1R oznacza czwartego kuzyna z jednym przesunięciem, czyli po angielsku "fourth cousin once removed"):
84, 15 (4C1R)
78, 15 (5C)
67, 15 (4C1R)
63, 11 (5C1R)
58, 10 (5C)
49, 10 (5C1R)
37, 13 (4C1R)
37, 10 (4C1R)
no match (4C1R)
Jak widać, nie ma ścisłej korelacji między stopniem pokrewieństwa a długością wspólnego DNA (oczywiście głównie dlatego, że jest to bardzo wąski przedział jeśli chodzi o różnice w stopniu pokrewieństwa). Co więcej, w jednym przypadku nie stwierdzono żadnego potencjalnego pokrewieństwa z tym moim piątym kuzynem, choć pokrewieństwo takie wykryto dla rodzonej siostry badanej osoby i kilku bardziej odlegle spokrewnionych osób z dwóch młodszych pokoleń (co pokazuje, z jak dużą przypadkową zmiennością mamy do czynienia).
Dla kontrastu podam też może najwyższy "fałszywie pozytywny" wynik, jaki udało mi się wykryć u członka mojej rodziny. Jeden z "matchów" mojego wujka (92 cM wspólnego DNA przy najdłuższym wspólnym bloku 43 cM) został w FTDNA sklasyfikowany jako drugi-czwarty kuzyn, a tymczasem brak jest tej osoby na liście "matchów" dla rodzonej siostry tego wujka, i nie ma go też na listach "matchów" dla żadnego z kilku jego przetestowanych pierwszych kuzynów (czyli stryjecznego/wujecznego/ciotecznego rodzeństwa ze strony ojca i matki).
Pozdrawiam,
Michał
{kind=link}